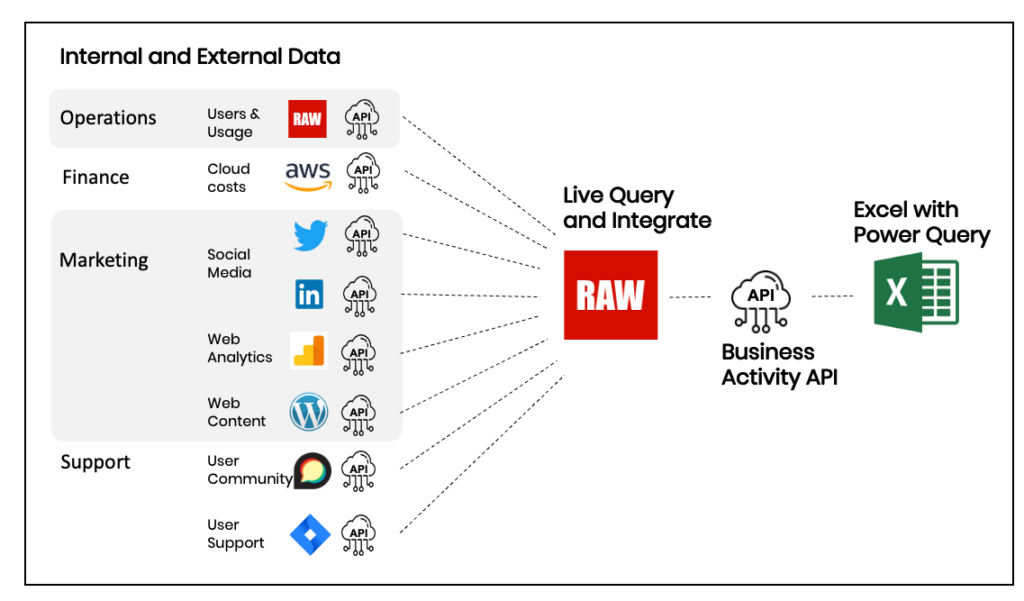
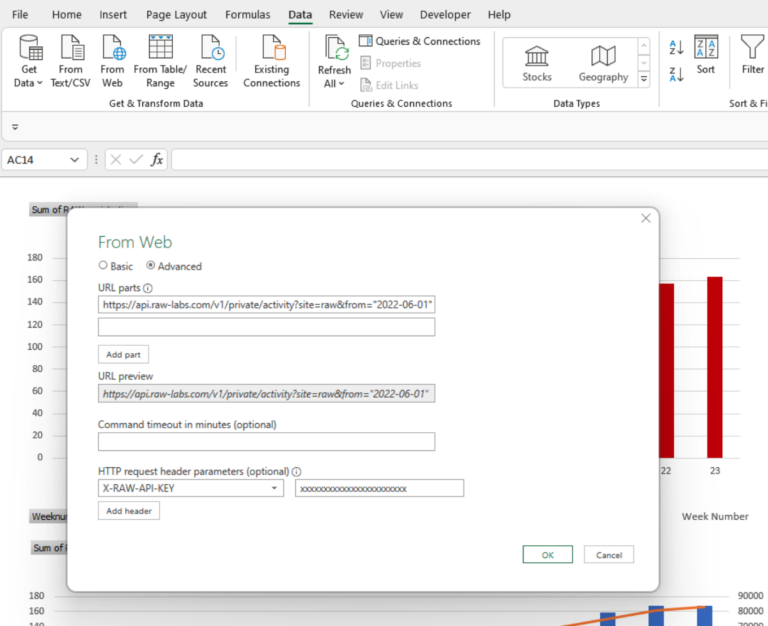
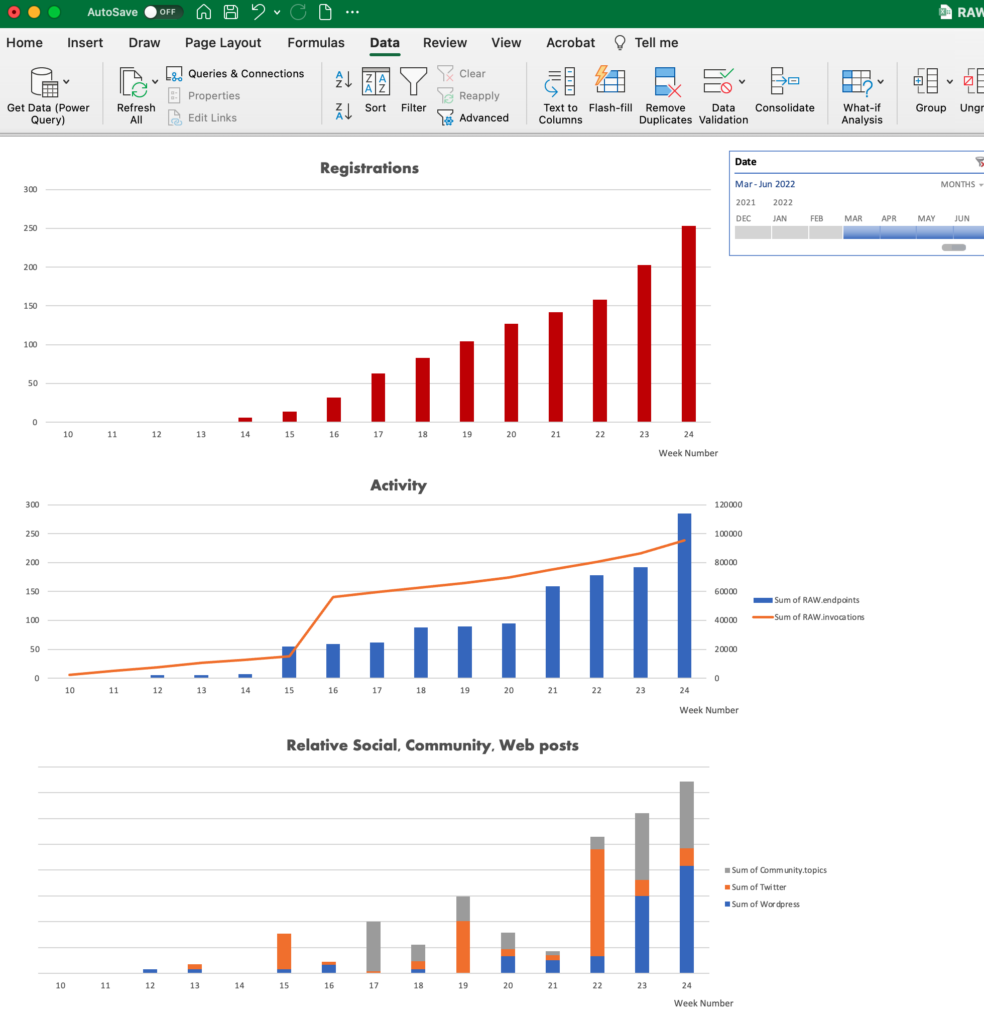
The Federal Statistical Office (FSO) is the national service provider of statistical observations in areas of national, social, economic, and environmental importance of the Swiss Confederation supporting policy making and decision support at operational, tactical and strategic level.
FSO is responsible for compiling and imparting user-friendly information on important areas of life in the Swiss society offering more than 15.5K data assets supported in three national languages. These data are currently available in a “human-readable” format in Excel files.
The challenge
Unfortunately, the Excel format prevents applications from easily consuming this data for analysis. Excel files include titles, multiple columns or tables, metadata, aesthetical components to improve human readability like line breaks or documentation.
Our approach
RAW enables the FSO to easily turn their vast collection of Excel data assets into accessible, ready-to-use machine-readable JSON datasets, provided as web services, which are more suited for data analysis.
The data assets were accessed, queried and processed using the Snapi language, a data manipulation language designed to deliver data quickly from multidisciplinary data sources. The data query and transformation process takes place in real-time by applying a number of dynamic transformation rules based on the Excel tables hierarchy as well as performing schema detection using inference. Out of all 37758 data assets, 37272 fit in the asset types and all of them were successfully transformed. Quality checks have been made on a selected subset, which is 2 samples per category per language. For these assets, RAW adopted an automated measurement and dimension naming checking system against the actual Excel assets. This QA approach can be extended with manual insertion of ground values (measurements in Excel files) for comparison against those in the JSON files.
The results
The converted data is now available in the RAW platform. Here's a brief guide in case you are interested in querying Switzerland's official statistical datasets.

The data assets can be consumed using three API endpoints:
- Retrieve a specific FSO asset given an FSO number in the original Excel format;
- Retrieve a specific FSO asset given an FSO number but in the converted JSON format;
- Search for assets given a set of criteria.
In particular, it's now possible to search across all Excel datasets, which was not possible in the past.
Let's look at each of these endpoints in detail.
To retrieve specific FSO asset given an FSO number in the Excel format use, e.g: https://sso.api.raw-labs.com/asset/excel?fsoNr=su-t-vz15-k-18.
To retrieve a specific FSO asset given an FSO number in JSON format use, e.g: https://sso.api.raw-labs.com/asset/json?fsoNr=su-d-vz18-b-0203.
The JSON assets contain the following information:
- Asset metadata: Information about FSO number, title, original URL of the excel file and various metadata used by the FSO (language, prodima & inquiry codes, period and embargo).
- Actual dataset: in the form of an array of records, each of which contains the following information:
- Administrative area (canton, commune or district)
- Actual measurement: copy of the respective excel worksheet
- Vertical dimension: hierarchical keys of the first column of each worksheet
- Horizontal dimension: flat (or hierarchical) keys found in first header rows
All assets are found in three languages (German, French and Italian), as indicated by their filenames. Below you can see the first lines for asset su-d-vz18-b-0203:
// 20230210160345
// https://sso.api.raw-labs.com/asset/json?fsoNr=su-d-vz18-k-10
{
"originAssetUrl": "https://dam-api.bfs.admin.ch/hub/api/dam/assets/97915/master",
"fsoNr": "su-d-vz18-k-10",
"language": "de",
"title": "Kanton Freiburg: Wohnbevölkerung nach Hauptsprache, Religion, Nationalität und weiteren Merkmalen",
"period": "2000",
"prodimaCode": "01",
"inquiryCode": "VZ",
"embargo": "09-Jan-2013",
"dataset": [
{
"measurment": "241706",
"Ausgewählte Merkmale I": "Wohnbevölkerung",
"Amtsbezirk": "Canton de Fribourg",
"Wohnbevölkerung_type": "Wohnbevölkerung_Total",
"Ausgewählte Merkmale II": "Wohnbevölkerung"
},
{
"measurment": "119837",
"Ausgewählte Merkmale I": "Wohnbevölkerung",
"Amtsbezirk": "Canton de Fribourg",
"Wohnbevölkerung_type": "Wohnbevölkerung_Männer",
"Ausgewählte Merkmale II": "Wohnbevölkerung"
},
{
"measurment": "121869",
"Ausgewählte Merkmale I": "Wohnbevölkerung",
"Amtsbezirk": "Canton de Fribourg",
"Wohnbevölkerung_type": "Wohnbevölkerung_Frauen",
"Ausgewählte Merkmale II": "Wohnbevölkerung"
},...
Finally, you can now search for assets given a set of criteria. This endpoint implements search for assets given a set of criteria. Supported criteria can be the following:
- fsoNr
- prodimaCode
- inquiryCode
- language
- titlePhrase
- period
- embargo
prodimaCode and inquiryCode definitions are provided by FSO as metadata. Search criteria are combined together in a logical AND relation. For example, if both titlePhrase and period are defined as input arguments, then the final results should contain both values. Users can retrieve the available search criteria values by calling one of the following classification retrieval services:
- prodimaCode:
https://sso.api.raw-labs.com/classifications/prodima - inquiryCode:
https://sso.api.raw-labs.com/classifications/inquiry - language:
https://sso.api.raw-labs.com/classifications/language - period:
https://sso.api.raw-labs.com/classifications/period - embargo:
https://sso.api.raw-labs.com/classifications/embargo
Regarding titlePhrase and fsoNr, simple words (or parts of words) can be defined. If the title or FSO number respectively contain the given phrase(s) then the asset is returned.
For example, to list all assets in french use https://sso.api.raw-labs.com/assets?language=fr.
To list all assets in french with title containing the phrase Bâtiments use https://sso.api.raw-labs.com/assets?language=fr&titlePhrase=Bâtiments.
To list all assets with 01.02.05 as prodimaCode with FSO number containing the fragment vz-AKL5_HG use https://sso.api.raw-labs.com/assets?prodimaCode=01.02.05&fsoNr=vz-AKL5_HG.
To learn more contact us.